小论文工作日记(一)
近期炼丹比较迷茫,没有改进思路了,读了几篇论文感觉知识在大脑滑过也没留下什么,输入不如输出,索性写点东西,梳理一下。
一、模型能学到什么?
前一段时间思考的问题是算力和先验的问题。VGGT的作者说:相信Data driver,我也相信,但是奈何算力不足,支撑不起庞大的模型,退而求其次转向设计先验特征。
在光度立体问题中,虽然先验信息很丰富,但是在所谓“通用”光度立体的问题下,意味着模型需要学习:
- 物体的几何形状,要理解阴影是什么
- 物体的材质信息,理解高光是什么,反射和二次反射
- 光源的位置信息,包括点光源、近场光、多光源
- 相机的透视矫正、gamma矫正等
近年的论文作者开始在场景下不同材质的问题上讲故事,这里就不展开了。
Transformer时代,很难说“特征”具体是什么,只能是拿消融实验去做对比。而端到端的训练,人为的指定这一部分是光源解码器,却不去显式的回归光源,这是一件说不清楚的事情,也不太好讲故事。
所以我认为,既然如此,就应该用“偏向数学”的先验。我不知道怎么形容,我看大家的论文其实都有这种数学上的强约束。
比如最早的PS-FCN[1],使用共享权重的编码器获取图像的特征,再pooling层融合。这暗含的信息是:输入的图像没有顺序信息,且输入信息同等重要。
同期的CNN-PS[2]是所谓逐像素的方法,即对每个像素点的法向量进行预测。这暗含的信息是:每个像素遵循同一套反射规律。
接下来阅读论文。从模型结构入手,寻找这些有趣的数学约束并分析。
二、 Universal-PS
先从逐像素的这一路研究开始聊吧。Ikehata 是CNN-PS的作者,随后在这一方向上持续发力。还是非常地道的作者,代码和数据集都开源。中间几年不知道干嘛去了,18年到21年竟然没有发表过论文。21年的PS-Transformer更像是复健,没公开数据集,就不聊那个了。从22年的UniPS开始。
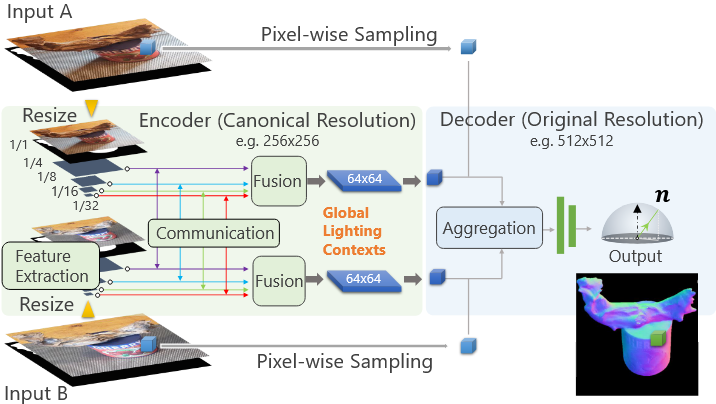
首先是提出了一个概念叫通用光度立体,即光源并非简单的点光源,在实际场景中,往往是复杂的混合光源,所以针对这种场景进行解决。不过我认为这个属于是讲故事的范畴了,和他的数据集相匹配,充实整个论文工作量的。
重点是他的网络结构。编码器是对整张图像进行压缩,压缩的比较小之后开始下采样融合,生成一个特征,使用PMA聚合单帧的信息输出一个向量。
解码器则逐像素推理,利用编码器编码得到的特征向量生成最终的表面法线。
我个人觉得他这种玩法,基本上固定死了编码器学习的是光源信息,可能还会学到一些材质信息。解码器则是学习什么是反射。不过整体上看网络结构是有一定美感的,就是图画的不咋地。
三、SDM-UniPS
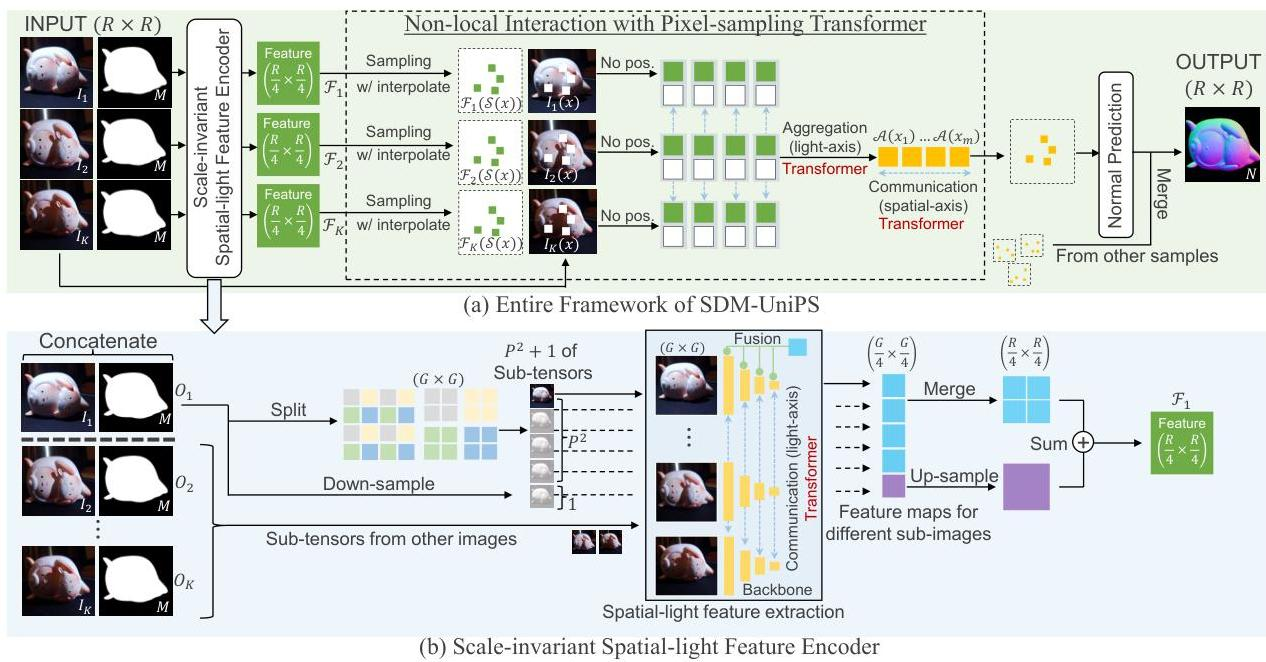
作者在23年继续小修小补,开始换模块:
首先是他觉得下采样对细节的恢复不好,于是进行分块操作,先把每张图分割成小块,然后做transformer,再把特征拼起来;其次不再选择PMA聚合特征,而是选择用金字塔网络融合。
其次是解码器,依旧是逐像素推理,与之前不同的是:首先是把位置信息剔出去了,只学习反射规律;其次并非孤立的对每个像素做回归,而是做了一次communication。
不过这里要对他的算法打个问号,训练的时候对整张图抽像素,推理的时候对小patch分块做,这个communication实际上在做迁移,这个效果还是要打个问号。
作者又做了一套数据集,更复杂的光源,更复杂的对象
四、GeouniPS
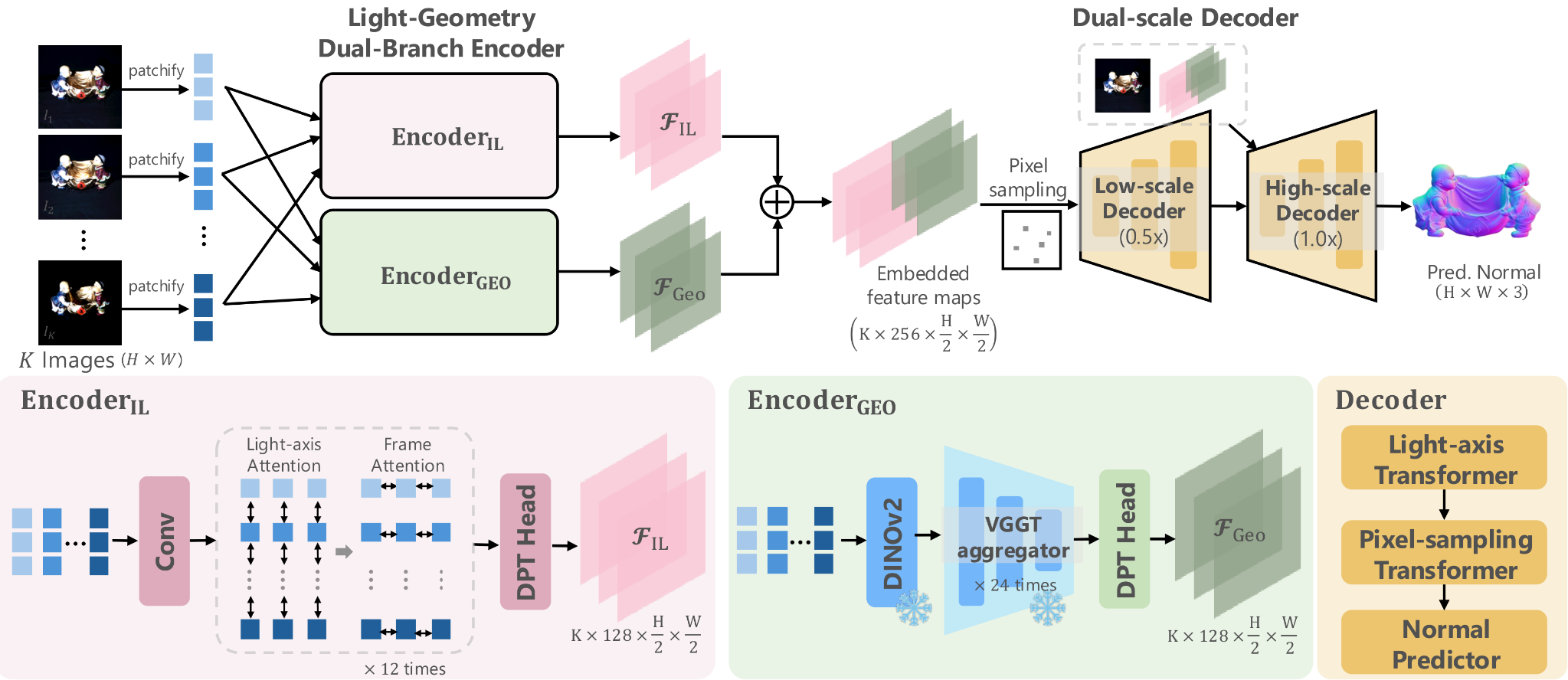
同一个组的论文,这回的架构算是大改了,编码器用VGGT的aggregator提取特征,作者认为是几何特征;然后感觉效果不好,又加了一个光源特征编码器;
解码器也是类似的,区别在于做了两次解码,低分辨率解码出的结果再送到高分辨率解码器中再解码一次,说实话这样的设计有点为了指标而指标的感觉了,还是不太优雅…
搜罗到了几个关键词:
尺度不变,平滑性,可积性,光轴,注意力热力图,后面在这里找点搞头
参考材料
[1] Chen G, Han K, Wong K Y K, 2018. PS-FCN: a flexible learning framework for photometric stereo[C]//Ferrari V, Hebert M, Sminchisescu C, et al. Computer Vision – ECCV 2018. Cham: Springer International Publishing: 3-19.
[2] Ikehata S, 2018. CNN-PS: CNN-based photometric stereo for general non-convex surfaces[M]//Ferrari V, Hebert M, Sminchisescu C, et al. Computer Vision – ECCV 2018: Vol. 11219. Cham: Springer International Publishing: 3-19.
[3] Ikehata S, 2022. Universal photometric stereo network using global lighting contexts[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, LA, USA: IEEE: 12581-12590.
[4] Ikehata S, 2023. Scalable, detailed and mask-free universal photometric stereo[A]. arXiv.
[5] Tam K M, Ikehata S, Asano Y, et al., 2025. Geometry meets light: leveraging geometric priors for universal photometric stereo under limited multi-illumination cues[A]. arXiv.