小论文工作日记(二)
今天堪称漫无目的的做了一个实验
一、DINOv3
昨天了解到有一个东西叫做attention map,可以可视化模型对图像的注意力程度,我第一个想起来的是DINO这样的ViT编码器,去年发布的DINOv3,所以就想看看他到底能学到什么特征
一打开github,看到这张图还是挺唬人的,如果这样的细节信息可以通过学习得到,那光源和材质什么的应该不在话下吧~

这张图是基于特征做余弦相似度,越相似的越亮,如果要是能跨图像提取光源信息,想想都觉得有搞头
把代码down下来跑一下!
原DINOv3是一个7B的大模型,然后用教师学生网络蒸馏出来的小模型,然后有一个ViT版本,一个ConvNeXt版本的。我个人理解就是transformer版本和cnn版本。
| 模型 | 参数 |
|---|---|
| ViT-S/16 | 21M |
| ViT-S+/16 | 29M |
| ViT-B/16 | 86M |
| ViT-L/16 | 300M |
| ViT-H+/16 | 840M |
| ConvNeXt Tiny | 29M |
| ConvNeXt Small | 50M |
| ConvNeXt Base | 89M |
| ConvNeXt Large | 198M |
不过也没有什么指标,光是这样看参数量是挺抽象的,vit base的模型大约342M,按FP32 4字节算,大致对的上。和DINOv2 的 86M比稍小一点,但是对于我们的显卡来说,还是略大,后面可以试试S版本的。此外和v2比,patch从14 * 14变成 16 * 16 对于数据集友好一点。
二、能学到什么?
作为一个特征提取器,当然是以能学到特征为指标,令人欣喜的代码中包含了PCA 的代码,即把一个特征进行可视化。比如原图是518的diligent, 他会先插值放大到768,然后 768/16 = 48 得到一个[768,48,48]的特征向量,再用PCA得到一个[3,48,48]的RGB图,再插值放大。我把DiLiGenT数据集中随机抽了几个场景,跑了一下可视化:

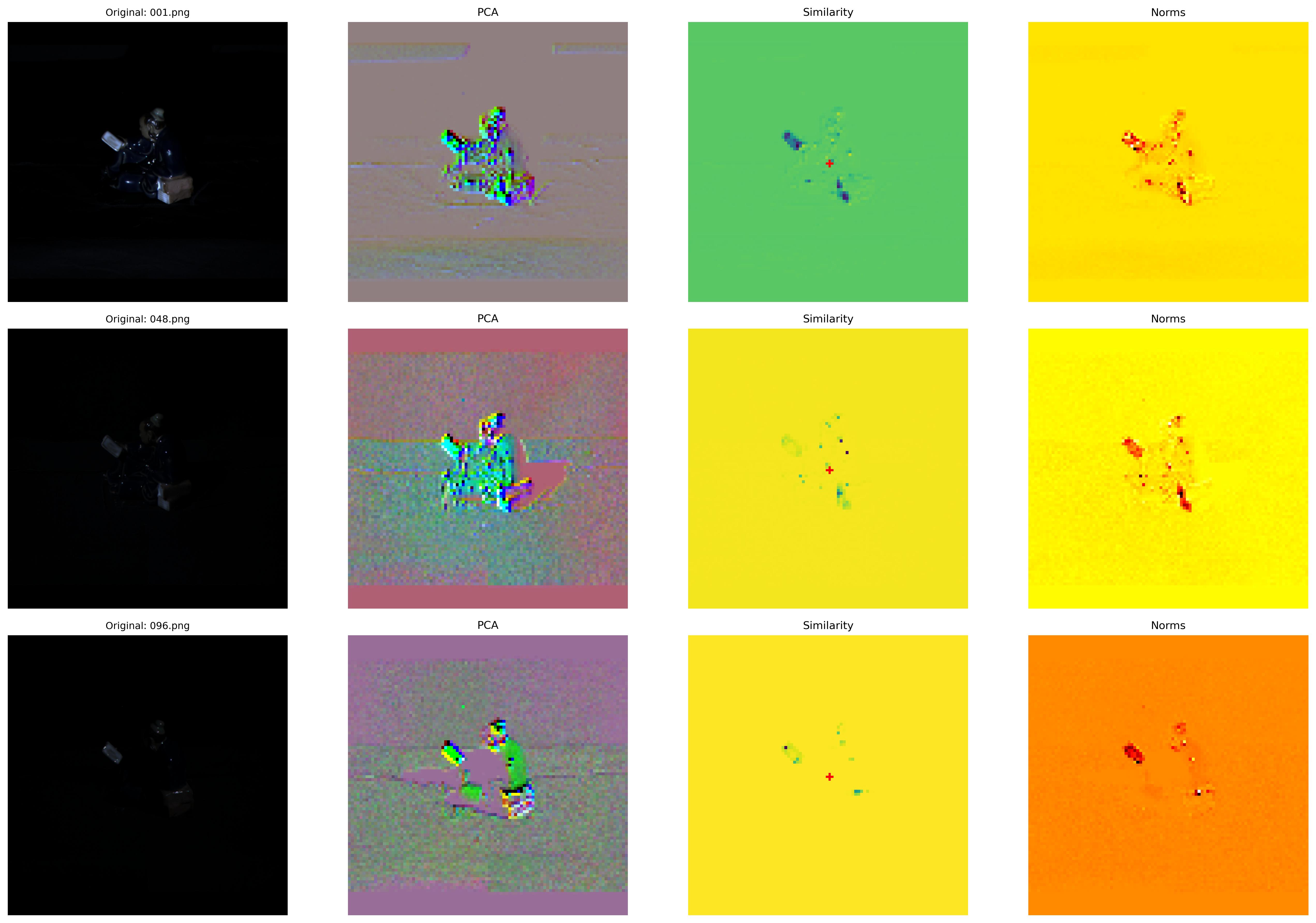
先解释一下都是什么:
PCA是简单的降维得到的结果
similarity是余弦相似度热力图,就说图像中心点的红叉和其他像素的余弦相似度,暂时没什么参考性
Norm是特征范数(向量长度),可以理解成注意力的热力图吧
从ball的PCA图中,可以非常清晰的看到模型对于方向有一定的理解,产生了近似法向量图的图;
从norm图中,可以看到模型对反射也有一定的理解,高光点与其他的图像并不一致;
从bear的similarity的图中,也可以看出模型对普通的漫反射和高光反射反应不同;
而对于比较复杂的reading, 模型对反光依旧敏感,但对于遮挡的地方视为了背景。
从这个结果中,可以认为DINO对漫反射,镜面反射有一定的理解能力,完全可以基于他输出的特征指导逐像素的光源回归。
如果特征可以解释,那真是一个非常令人感动的事情,不过现在看效果还是不错的,唯一有个几个问题是:
按照AI给我的说法,norm图越亮应该是越感兴趣,越暗越不感兴趣,但是部分图中背景比高光还亮,也就意味着模型对背景更感兴趣?
最后我又测试了一下small的热力图:
肉眼上看不出区别,那后面就用small节省一点内存吧~
想吐槽一下Meta,下载Dino的权重文件的时候还被拒绝了,网上搜索了一下,不能填中俄,因为被制裁了 - -
说好的学术无国界呢!~
那我还能用这个编码器写论文吗~
然后发现了一个好用的国内镜像站概览 · 魔搭社区比HF-Mirror好用太多!
三、后续安排
后面我打算基于SDM-UniPS 开始改进,VGGT还是太重了,主要做改进的点在于如何融合多帧信息。首先用现有的SDM-UniPS模型结构先跑通一个大概的结果。
嗯…如果是这样的话,今晚睡前挂一个模型先训练试试看,然后明天想个办法把DINO嵌进去